|
Overview
When establishing standards, it is a common task to determine
similarities between variable names and labels. This will help you
establish standard variable names or match variables to a particular
standard. The MATCHVAR automates this process by generating a report
capturing the similarities between selected datasets. You can
control how tolerance of the match with a score of 1 to 5. Where 5
is most loose and 1 is a very tight fit.
MATCHVAR
Options
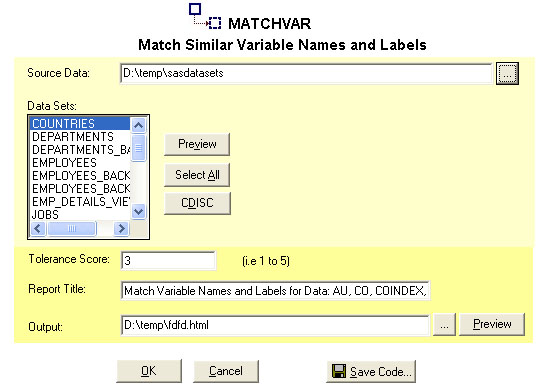
The MATCHVAR screen allows you to select the data which to be included
in the evaluation of matching variables. The data flow for this tool is shown here.
|
Source Data |
 |
CDISC Builder
MATCHVAR |
|
MATCHVAR HTML reports |
|
The options available for
selecting data and options for MATCHVAR are:
- Source Data - This is the
location of the dataset that is going to be used to perform the match
variable analysis.
- Datasets - Source datasets that
are used to for MATCHVAR.
- Preview - A preview of the
first 100 observations of the data that is selected.
- Tolerance Score - The score
between 1 and 5 which controls the degree of how closely the match
should be. A score of 1 is a very tight fit where a 5 is a very
loose fit. You can choose any values in between.
- Report Title - The title of the
report.
- Output - The output HTML report
index page name of the report. There will be two other pages
created based on this name which stores the details of the report.
 |
The MATCHVAR can be applied
to many datasets within the specified source location data path at
one time. |
|